Create an experiment
A step by step guide to creating a new experiment in ABsmartly.
Getting started
To get started with creating a new experiment, you can click Experiments on the left side menu and then choose Create from Scratch.
Instead of creating an experiment from scratch you can also decide to use a pre-existing template. To find out more about creating and using templates check our template documentation.
Basics
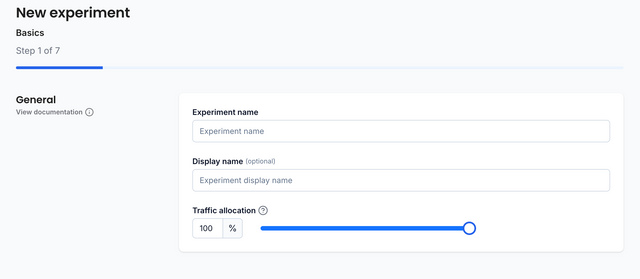
The Basics step is where you will define the experiment name, display name and set the traffic allocation.
Experiment Name
The experiment name needs to be unique but it can be anything that you want! As it will be used in your code, we recommend using camel case or snake case.
Because experiment names are unique across the entire platform, it is usually good practice to use a naming convention. A good experiment name could for example include a team name, a project name, etc.
<team-name>-<project-name>-<experiment-name>
Display Name
The display name is how the experiment will appear in the ABsmartly interface. The display name does not need to be unique. As this name will be used to identify your experiment in ABsmartly, we recommend using a good human readable name.
Traffic Allocation
The traffic allocation is the total number of eligible visitors who will be included in the experiment, including the control group. Usually, this is kept at 100% unless the change is considered dangerous. In which case, you could start it at 10%, move it up to 50% and eventually to 100% as you grow more confident in the change.
Variants
The variants section is where you will choose the number of variants for your experiment, the percentage of traffic that each variant will have, your variant names and set any variant variables which can be used in your code.
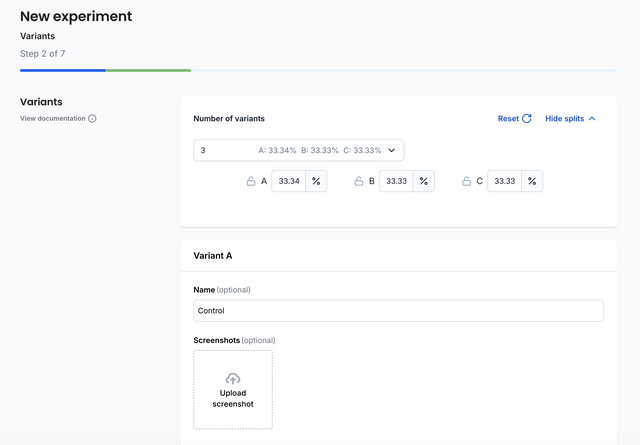
Variant Split Manager
The Variant Split Manager is where you can select your number of variants and the percentage of traffic to assign to each one of them.
Your experiment can be configured with up to 4 variants (control + 3). The percentage of traffic for each variant can be set separately for each variant as long as the total adds up to 100%.
The percentage of traffic in each variant cannot be changed once the experiment is started. Doing so would introduce bias into the results. If you wish to ramp up an experiment, it's better to use the traffic allocation option instead. For a multi-variant experiment to be eligible for Group Sequential Testing, it requires an equal split between variants (excluding control).
The more variants you have, the less traffic each variant will be exposed to and the longer it will take for the experiment to finish. The optimal set up is an A/B experiment with a 50/50 split in traffic.
Variant Variables
Variant variables can be used to automate your experiments. If you, for example, use a configuration file, you can pass a variant variable here and have it overwrite your code. See treatment variables in the SDK Documentation for more information.
We do not recommend changing variables on your control variant (Variant A).
Variant Screenshots
Screenshots can be added to visualise the changes introduced in each variant of an experiment. Screenshots are useful to quickly understand what an experiment is changing.
Audiences
The audiences’ step is where you will control where the experiment will run and who will be exposed to it.
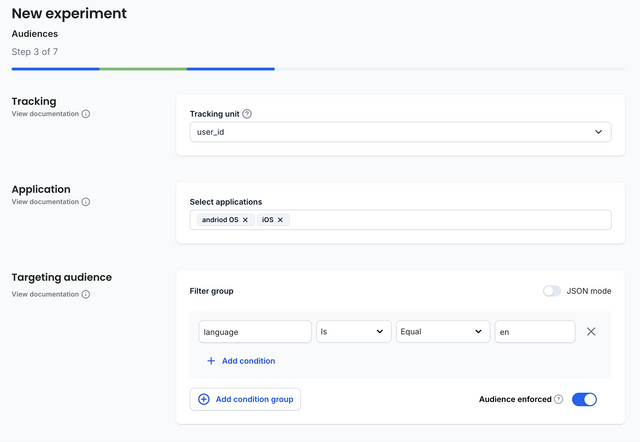
Tracking Unit
The tracking unit refers to the unique identifier used to identify the visitors of your experiment.
If the experiment is to be run across multiple platforms (Such as iOS, Android, Web, Email etc.), then this unit should be available on all of them, for example, the user_id of the authenticated user.
If the experiment is to run on a part of the product where visitors are not logged in, then an anonymous identifier stored in a cookie can be used to identify visitors.
ABsmartly does not create nor use any third-party cookie. It is the responsibility of the experimenters to provide a unique identifier for the visitors of the experiment and if needed to store it in a first-party cookie.
You can create new tracking units (there is no limit to the number of identifier you create) in your dashboard settings.
Applications
Applications defined where this experiment will run. An experiment can be running on several platforms at the same time.
These could be android, ios and web, for example, and are also created in your dashboard settings.
Targeting Audience
In this section you can define which particular audience will be exposed to the experiment. For example, you could decide to only run the experiment for visitors on an android device or visitors whose language is set to english.
In this case you might set the filter group to:
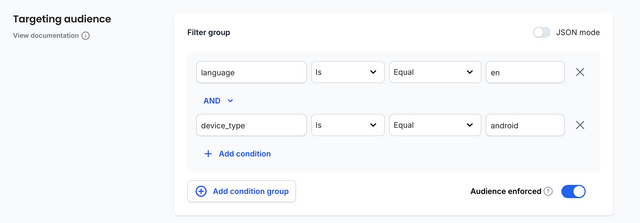
These audience parameters can then be passed to the SDK in your code using context attributes.
Audience Enforced
When audience enforced is on, only users in the filter groups will be exposed to the experiment. Others will be shown the control variant, but their data will not be tracked.
When audience enforced is off, it is the responsibility of the experimenter to ensure that only eligible visitors are shown the experiments. ABsmartly will only warn you when visitors not matching the audience are exposed to your experiment. In this case you would see an audience mismatch warning in your experiment. This option makes it easier to full-on when the experiment is completed as the audience filtering is not part of the experiment set up.
Exclusion Rules
Exclusion rules let you define which visitors or groups of visitors should be excluded from the experiment and instead always see a specific variant.

When to Use Exclusion Rules
Exclusion rules are useful in two main scenarios:
- Testing & QA — Force yourself or your team into a specific variant to verify the experience before or during the experiment, without being counted as a participant.
- Internal or beta users — Ensure that a specific group of users (e.g. internal employees, beta testers) always sees the new variant without polluting the experiment data.
How It Works
An exclusion rule defines:
- Who to exclude — A set of conditions that identify the visitors to exclude, based on context attributes (e.g.
user_type = internal,email ends_with @yourcompany.com). - Which variant to show — The variant that excluded visitors will always be assigned to.
Excluded visitors are not part of the experiment. They will see the assigned variant but their data will not be tracked or included in the experiment results.
You can add multiple exclusion rules to a single experiment. Rules are evaluated in order — a visitor matching any rule will be excluded.
Example
To exclude internal users and always show them Variant B:
| Condition | Variant |
|---|---|
user_type equals internal | Variant B |
This ensures your team can experience the new variant in production while keeping the experiment data clean.
Exclusion rules require an SDK update. Make sure your SDKs are up to date before using this feature. See the SDK documentation for details.
Metrics
In this section you can define the metrics to use to test your hypothesis and to measure the impact of your experiment. You can learn more about experimentation metrics in our Understanding Experimentation Metrics article.
The Primary Metric
The Primary Metric is the main metric you are trying to impact as a result of the change. This is the metric which ABsmartly uses to compute the test statistics and it is the main metric which will be used to decide if the hypothesis is tested or not. Choosing the right Primary Metric is one of the most important parts of the experiment set up.
Choosing the right metrics can be hard. Below are the main characteristics to consider when choosing your Primary Metric.
Aligned: Does it reflect the hypothesis? The metric should directly reflect the business objective or user outcome that the experiment is intended to improve. This alignment ensures that the experiment results drive meaningful business decisions.
Stable and Reliable: Can it be trusted? The metric should have low variability and provide consistent results over time. This minimizes noise and ensures that observed differences are due to the treatment rather than random fluctuations.
Sensitive: Does it respond to the change being tested? A good metric should respond detectably to the changes being tested, even for small effects. Sensitivity helps detect meaningful differences without requiring excessively large sample sizes.
Actionable: Does it provide clear & actionable insights? The metric should guide decisions. If the metric increases or decreases, it should provide a clear indication of whether the treatment should be implemented or iterated on.
Measurable: Can it be tracked reliably? The metric should be easy to measure accurately and consistently across all experimental conditions.
To ensure that experiments are aligned with overall strategic objectives it is good practice, when possible, for the primary metric to measure the impact of the change on a key business metric. To ensure consistency and alignment across all decisions, it is advised for all experimenting teams (within a reasonable scope) to agree on and to share the same primary metric.
To understand how the primary metric is used to make good informed decisions, check our article on interpreting results and making decisions.
The Secondary Metric(s)
Beside the primary metric, it is possible in ABsmartly to add secondary metrics to your experiments. Secondary Metrics are not the main criteria for decision-making but help ensure a comprehensive understanding of the experiment’s impact. They provide additional context and insights beyond the primary metric and can help to detect unintended side effects and support what was observed on the primary metric.
While the primary metric usually measures the impact on the business, secondary metrics are more often (but not always) behavioural metrics, directly measuring the impact of the change on the visitors' behaviour.
If you observe a significant impact on the primary metric but no significant differences on the secondary metrics then the impact observed on the the primary metric is likely a false positive. For more information, check our article on interpreting results and making decisions.
The Guardrail Metric(s)
Guardrail Metrics are safeguards and they used to monitor and ensure the health, stability, and overall integrity of the system during an experiment. They do not measure the success of the primary business objectives but are critical for detecting unintended negative impacts on the business, user experience and/or operational performance. They act as early warning systems, identifying potential risks such as degraded performance, increased errors, or adverse user behavior before they escalate into larger problems. ABsmartly allows you to monitor your Guardrail Metrics (and others) in real-time to ensure experiments are safe and do not unintentionally harm other parts of the business and/or some key system performance. (Learn more)
Characteristics of good Guardrail Metrics:
Protective: Ensure that key aspects of the system, such as performance, reliability, and user experience, remain unaffected by changes.
Comprehensive: Cover diverse dimensions of potential harm, including technical, operational, and customer-centric aspects.
Non-Negotiable: A breach in guardrail metrics often halts or reverses an experiment, even if the primary metric shows improvement.
It is good practice to have a set of guardrail metrics agreed upon and shared by all experiment teams (within a reasonable scope) so all decisions are made with the same understanding of their overall impact.
To improve their usefulness, it is possible to define on the metric’s page, a threshold at which an alert would be triggered so you don’t miss it. Depending on the severity of the issues they signal, Guardrail Metrics can be used both for early stopping of experiments and to assess their impact at decision time.
For more information on early stopping of experiments using ABsmartly you can read our early stopping guide.
The Exploratory Metrics
Exploratory Metrics are simply used for curiosity. They should have no impact on the decision making process. Exploratory metrics are mainly used for deep dives into an experiment's impact. Exploratory Metrics are mainly used for debugging but may be used to infer new hypotheses.
Adding Exploratory Metrics to your experiment will make them visible on the experiment's dashboard but you can always look at more metrics from the metrics' explorer.
To avoid biases, and unless you are debugging an issue, it is recommended to not look at the Exploratory Metrics during the runtime of the experiment.
Example of experimentation metrics
Below are a few examples of what Primary, Secondary and Guardrail metrics could be depending on your industry and your product.
| Industry | Primary Metric | Secondary Metrics | Guardrail Metrics |
|---|---|---|---|
| E-commerce | Conversion Rate | Average Order Value (AOV),Cart Abandonment Rate,Add To Cart | Page Load Time,Payment Failure Rate,Customer Support Tickets |
| Airline | Ticket Purchase Rate | Seat Upgrade Rate,Ancillary Revenue,Booking Abandonment Rate | Flight Cancellation Rate,Customer Complaint Rate,Search Load Time |
| Online Media/Streaming | Engagement Time | Content Completion Rate,Churn Rate,Recommendation Click-Through Rate | Video Playback Failure Rate,App Crash Rate,Buffering Time |
| Health & Fitness App | Active Days Per Week | Workout Completion Rate,App Session Length | App Uninstall Rate,App Crash Rate,Support Ticket Rate |
Cannot find your metric in the list? Make sure it is active as draft metrics cannot be added to experiments.
Analysis
In this step, you can choose and set up the analysis type you want to use. To choose between a Group Sequential or Fixed Horizon analysis check our analysis type article.
To continue to properly set up your experiment refer to the relevant setup guide
Metadata
The metadata step is where you can fill in details about your experiment that may help others to understand what you hope to achieve with it.
Metadata
The metadata section allows you to select the owners of this experiment, assign it to a particular team and add tags to help with searching and filtering later on. These fields may be required, optional or hidden depending on your company's platform settings.
Tags
Tags can be named anything you like. Often it can be useful to prefix your tags with the meaning of that tag. Some examples of tags could be:
stack:backendtheme:urgencylocation:navbarpsychological:trust
These allow for you to filter your experiments in the experiments list page, but they also give you an insight into why that experiment was tagged as such.
Description
When creating a new experiment, the description section acts as your contract for the test. Allowing you to define for yourself and your team why you are running this experiment, what you hope for the result to be and what will be done after any of the experiment's possible outcomes. The following are our default fields, but they may be different depending on your company's platform settings.
Hypothesis
Your hypothesis is the assumed answer to the question that the experiment is asking.
For example:
Based on the fact that the color red is one of the most visible colors in the color spectrum, we believe that red call-to-action buttons are more noticeable on screen than blue ones.
Prediction
Your prediction states what will happen if your hypothesis proves to be true.
For example:
Changing our call-to-action buttons to red will cause a higher click-through-rate to our checkout page from our visitors.
Purpose
Your experiment's purpose is the reason for why this experiment should take place. What customer or business needs are being addressed.
For example:
Optimizing the efficiency of our sales pipeline.
Implementation Details
In your implementation details, you can define the parameters of your experiment's implementation, like:
- How long it will take to implement
- What's the impact that we can expect from this implementation?
- What is the minimum impact that we need to see in order to keep this experiment?
For example:
This implementation will be completed by Friday 20th.
We can expect an increase of up to 25% in our homepage click-through-rate.
At a minimum, we should see a 5% increase if we are to keep the change.
Action Points
Action Points are a list of actions that will be taken depending on the experiment's outcome.
For example:
If the primary metric is significantly positive we will keep the experiment.
If the primary metric is significantly negative we will drop the experiment.
If the primary metric is inconclusive we will drop the experiment.