Setting up a Group Sequential Experiment
A step by step guide to set up and configure a Group Sequential experiment.
Type of Analysis
A Group Sequential test can be configured on the Analysis step (Step 5) of the experimentation setup. To understand the differences between Group Sequential and Fixed Horizon experiment check our analysis type article.

The default type of analysis for your experiments can be defined in your platform settings.
For a multi-variant experiment to be eligible for Group Sequential testing it requires an equal split between all variants (excluding the base variant A). This variant split is defined on the Step 2 (Variants) of the experiment setup.
Error control
In this section, you can choose the confidence and power levels for your experiment.

Confidence measures the probability that you would not incorrectly reject the null hypothesis when it is true. In other words, it reflects how sure you want to be that a result is not due to random chance. For example, if your confidence level is 90%, you have a 10% chance of a false positive error (rejecting the null hypothesis when it is actually true). Confidence ensures your findings are robust and minimizes misleading conclusions from noise.
The confidence reflects the confidence level for a 2-sided analysis. A 2-sided analysis means that we are testing in both direction, looking for superiority and inferiority. A 90% confidence in a 2-sided analysis (like we use in Fixed Horizon), means a 5% false positive on each side of the interval (5% of the false positive will be significantly positive and 5% will be significantly negative) Our Group Sequential uses a one-sided analysis (it only look for superiority and makes no distinction between negative and inconclusive). For consistency and alignment between analysis types, we still ask for the confidence as if it was a 2-sided analysis but adjust it accordingly to reflect the 1-sided analysis.
To summarise: If you specify a 90% confidence for your GST, the experiment will actually be set up with a 95% confidence level which equals to a 5% false positive.
Power refers to the ability of a test to detect a true effect when it exists. For example, a power of 80% means the test has an 80% chance of correctly identifying a real effect as small as the MDE. Power ensures your experiment is sensitive enough to detect meaningful changes, especially in cases where the effect sizes are small.
The minimum and default values for confidence and power levels for your experimentation program can be defined in your platform settings.
Primary metric
To continue setting up your Group Sequential experiment, you first need to select your primary metric.
Choosing the right primary metric can be hard. Below are the main characteristics to consider when choosing your primary metric.
Aligned: Does it reflect the hypothesis? The metric should directly reflect the business objective or user outcome that the experiment is intended to improve. This alignment ensures that the experiment results drive meaningful business decisions.
Stable and Reliable: Can it be trusted? The metric should have low variability and provide consistent results over time. This minimizes noise and ensures that observed differences are due to the treatment rather than random fluctuations.
Sensitive: Does it respond to the change being tested? A good metric should respond detectably to the changes being tested, even for small effects. Sensitivity helps detect meaningful differences without requiring excessively large sample sizes.
Actionable: Does it provide clear & actionable insights? The metric should guide decisions. If the metric increases or decreases, it should provide a clear indication of whether the treatment should be implemented or iterated on.
Measurable: Can it be tracked reliably? The metric should be easy to measure accurately and consistently across all experimental conditions.
If the metric you are selecting is not new and we have already collected data for it, you will see a button to show the metrics performance graph.
This graph shows the metric's variance and standard deviation over the last 6 weeks for your selected platform(s) and tracking unit (for performance reason, the underlying query samples 10% of overall visitors to compute the results). This is an indication of what you can expect if you start your experiment now with this metric as your primary metric. To ensure an optimal Group Sequential analysis, it is critical that the metric's variance and standard deviation have stabilized enough at the moment of the first analysis (you can see that when the graph flattens out). To do that ensure that the first analysis happens only once the variance has stabilized enough, you can adjust the time to first analysis below.
If the metric's variance is still high at the time of the first analysis, the participant and date estimates of each interim analysis will be less precise which can lead to confusion and make it harder to plan around.
If the metric's graph shows an ever increasing variance then it is an indication that this metric might not be a suitable primary metric for your GST experiment. If this is the case you can either choose a more suitable metric (with less variance) or you can look at reducing the metric's variance (for example by introducing a time filter and/or outliers filters). If you have questions please reach out to our support.
Group Sequential Testing Setup
This is where the actual configuration of the Group Sequential Test takes place
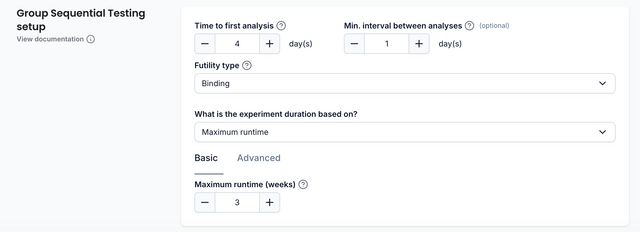
Time to first analysis
The time to first analysis defines the moment at which the first interim analysis will take place. The first analysis is a special analysis as it is when the full design of the experiment is calculated (how many interim analyses, date for each analysis, etc). The GST engine uses some data it has collected since the start of the experiment to fine tune the setup. For example daily visitors, the metric's variance and the standard deviation. As mentioned above, it is important those numbers have stabilized enough by the time this analysis takes place otherwise the interim analysis setup will not be as precise.
The time to first analysis is also meant to capture business cycles and to reduce some biases which might be introduced by running an analysis too early. Running an analysis too early in the experiment could lead to significant results which are biased and not representative of the entire population (for example by having a non-representative sample of visitors, too many frequent users, too many weekend users, etc).
Make sure to choose a time to first analysis which takes those constraints into account.
It is often a good practice to run experiments for at least one week so it captures visitors throughout the week. This is often important as Monday visitors could react diffently to changes than week-end visitors.
Minimal interval between analysis
Optionally, it is also possible to specify a minimum interval between each interim analysis (defined in days). Interim analyses will not happen more often than specified. While the GST engine will use this parameter in the setup it cannot guarantee that each interim analysis will happen at this precice interval. In practice time between analysis will probably be larger than the specific minimum interval as it is dependant on many factors, for example, the maximum number of possible analyses (currently 11), MDE, daily visitors counts, metric variance, etc.
As with the time to first analysis, this can be useful to ensure a good representative sample of visitors at each interim analysis.
Having the right number of analyses can help maximize the benefit of Group Sequential Testing. Too many interim analyses lead to a decrease in power which will mean a longer runtime on average. Too few interim analyses lead to less agility and velocity and does not maximize the value of GST. Defining how often you want interim analyses run is key but it's also very depend on the context and might require a few tries before you find the sweet spot.
Futility Type
Futility type defines what happens when the experiment crosses the futility boundary. There are two possible futility type, binding or non-binding. A binding futility type means that the experiment is completed as soon as it crosses the futility boundary. There will be no further interim analysis and a decision can be made. A non-binding futility type, on the other hand, means that the experiment will continue even after it has crossed a futility boundary. While a binding set up is the preferred, there might be cases when you want to continue running the interim analysis even once a futility boundary was crossed. This could be the case for example if you have a longer action cycle and it might take more time for the true impact to be measurable.
While non-binding futility offers more flexibility, it also decreases power and can increase the risk of making incorrect decisions if you choose to ignore the futility signal.
What is the experiment duration based on?
In this section you decide how the maximum duration of the Group Sequential test will be calculated. It can either be based on a Minimum Detectable Effect (the smallest effect the experiment is designed to detect at the given power and confidence levels) or on a possible Maximum Runtime.
Below we explain how each can be set up.
Experiment duration based on MDE
You provide a MDE and the experiment duration will be defined based on that value.
Basic
In the basic mode you can simply enter the MDE in the text field.
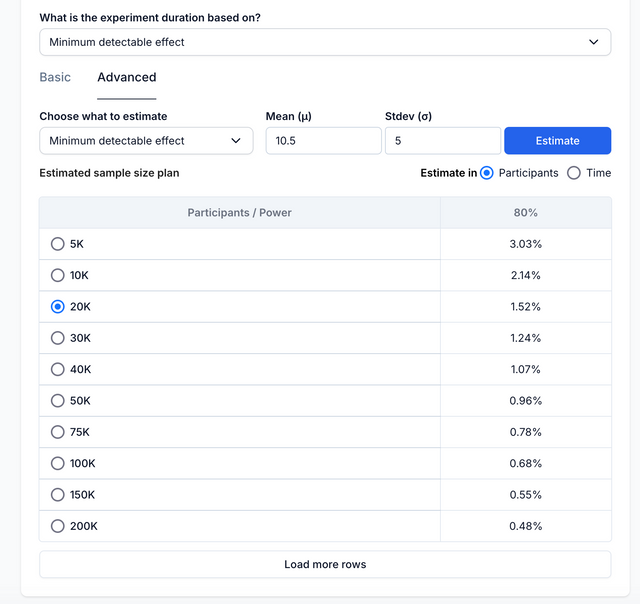
Advanced
In the advanced mode you can choose a MDE using the built-in power table. To estimate the MDE you need to input the conversion rate for binomial metrics or the mean and standard deviation for continuous metrics. Using the power table you can then choose a relevant MDE based on runtime or sample size for the power level you selected above.
Experiment duration based on Maximum runtime
You can use this feature if you wish your experiment to run for no longer than X weeks.
Because GST are one-sided experiments, they will always cross either one of the boundaries at the end of the runtime.
Basic
In the basic mode you can simply enter the maximum number of weeks you want your experiment to run. The maximum runtime cannot be shorter than the time to first analysis. If the time to first analysis is 10 days, then the smallest maximum runtime for the experiment will be 2 weeks.
Advanced
In this advanced section you have a power table which estimates the MDE at weekly intervals so you can choose a maximum runtime accordingly. To estimate the Maximum runtime you first need to input the conversion rate for binomial metrics or the mean and standard deviation for continuous metrics. You will also need to provide the estimated visitor count.
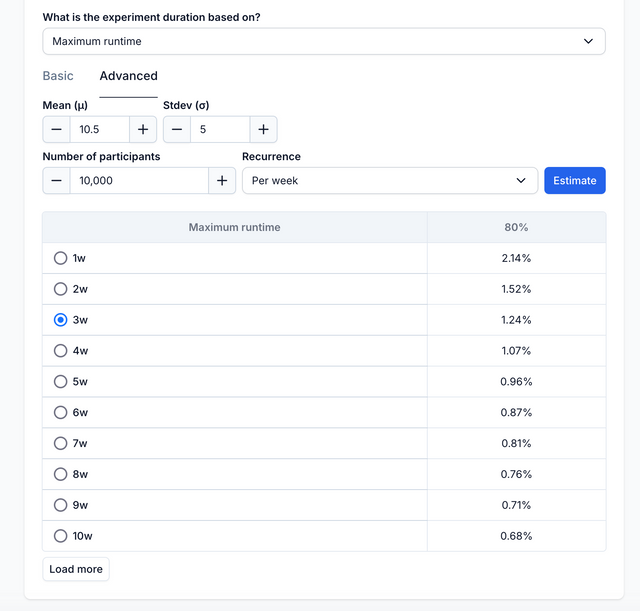
You can then choose a Maximum Runtime based on the MDE which can be detected at the defined power level.